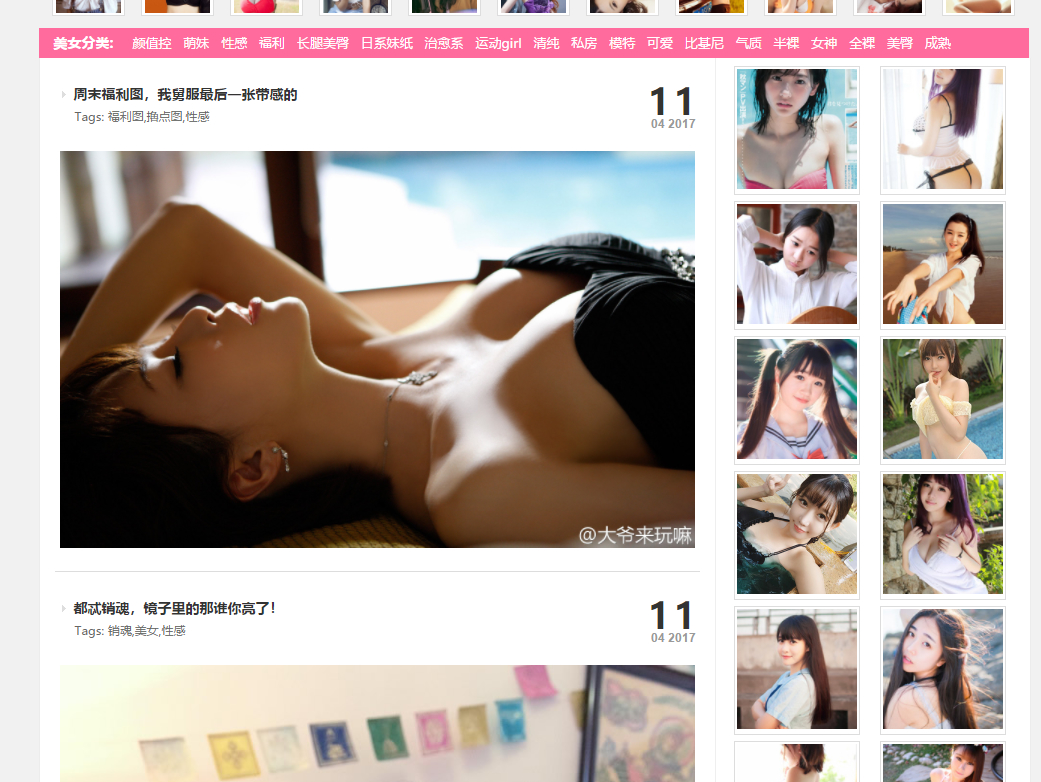
妹子图官方网址:https://www.mzitu.com/
刚接触到 BeautifulSoup,所以拿来试下效果,起伏跌宕出来效果。
具体思路?官网首页链接--> 获取分页面链接--> 通过分页面获取图片链接
看下步骤:
头部信息:
url = "https://www.mzitu.com"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
"Referer": "https://www.mzitu.com/101553"
}
def load_page(url):
try:
res = requests.get(url,headers=headers)
if res.status_code == 200:
print('页面请求完毕')
return res.text
except:
print('网络访问错误')
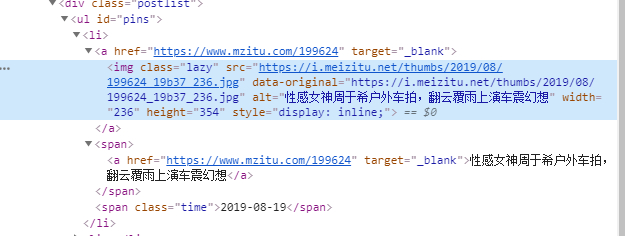
把如上页面可以抓取到当前页面所有女神合集 page。
def get_page(url):
html = requests.get(url,headers=headers)
soup = BeautifulSoup(html.text,'lxml')
#获取首页所有妹子页面
all_url = soup.find("ul",{"id":"pins"}).find_all("a")
# print(all_url)
count = 1
for href in all_url:
count=count+1
# print(href)
if count %2 != 0:
href1 = href['href'] #查找匹配出分页面中的page链接
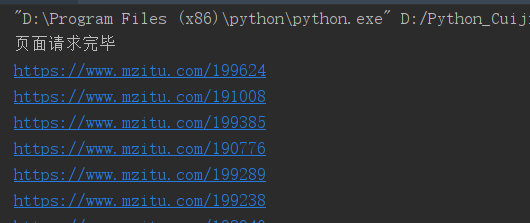
因为通过 for 循环得到的 href 链接是一样的,所以只取一个:取奇偶

结果如下:
for href2 in href:
res2 = requests.get(href1,headers=headers)
soup2 = BeautifulSoup(res2.text,'lxml')
# pict_url = soup2.find("div",{"class":"main-image"}).find("img")['src'] #图片链接
# print(pict_url)
next_pic = soup2.find_all("span")[9]
max_url = next_pic.get_text()
# print(max_url)
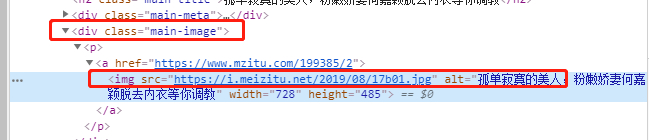
name = soup2.find("div",{"class":"main-image"}).find("img")['alt'] #分页面名称
os.mkdir(name)
os.chdir(name)
通过如下图的当前 page 中图片最后一张对应的 span 标签为第 9 个。

标题获取:
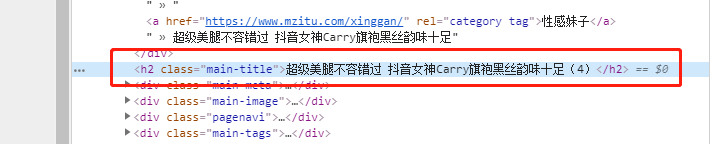
图片的对应链接如下:

图片链接获取如:
for i in range(1,int(max_url)+1):
next_url = href1+'/'+str(i)
res3 = requests.get(next_url,headers=headers)
soup3 = BeautifulSoup(res3.text,'lxml')
pic_address = soup3.find("div",{"class":"main-image"}).find('img')['src']
title = soup3.find('h2')
name1 = title.get_text()
img = requests.get(pic_address,headers=headers)
with open(name1+'.jpg','wb') as f:
f.write(img.content)
大功告成:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019/8/20 15:39
# @Author : cuijianzhe
# @File : meizitu.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time
import os
url = "https://www.mzitu.com"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
"Referer": "https://www.mzitu.com/101553"
}
def load_page(url):
try:
res = requests.get(url,headers=headers)
if res.status_code == 200:
print('页面请求完毕')
return res.text
except:
print('网络访问错误')
#获取整个页面
def get_page(url):
html = requests.get(url,headers=headers)
soup = BeautifulSoup(html.text,'lxml')
#获取首页所有妹子页面
all_url = soup.find("ul",{"id":"pins"}).find_all("a")
# print(all_url)
count = 1
for href in all_url:
count=count+1
# print(href)
if count %2 != 0:
href1 = href['href'] #查找匹配出分页面中的page链接
# print(href1)
for href2 in href:
res2 = requests.get(href1,headers=headers)
soup2 = BeautifulSoup(res2.text,'lxml')
# pict_url = soup2.find("div",{"class":"main-image"}).find("img")['src'] #图片链接
# print(pict_url)
next_pic = soup2.find_all("span")[9]
max_url = next_pic.get_text()
name = soup2.find("div",{"class":"main-image"}).find("img")['alt']
os.mkdir(name) #第一张图名称作为目录
os.chdir(name)
for i in range(1,int(max_url)+1):
next_url = href1+'/'+str(i)
res3 = requests.get(next_url,headers=headers)
soup3 = BeautifulSoup(res3.text,'lxml')
pic_address = soup3.find("div",{"class":"main-image"}).find('img')['src']
title = soup3.find('h2')
name1 = title.get_text()
img = requests.get(pic_address,headers=headers)
with open(name1+'.jpg','wb') as f:
f.write(img.content)
if __name__ == '__main__':
load_page(url)
get_page(url)
参考文档:
BeautifulSoup 中文文档
Requests 文档
 邯城往事
邯城往事