pip install pywin32
pip install Twisted
查看版本:
C:\Users\cjz>python -m scrapy version
Scrapy 1.8.0
D:\python_cuijianzhe>scrapy startproject scrapy_test
New Scrapy project 'scrapy_test', using template directory 'd:\programs\python\python37\lib\site-packages\scrapy\templates\project', created in:
D:\python_cuijianzhe\scrapy_test
You can start your first spider with:
cd scrapy_test
scrapy genspider example example.com
查看 scrapy 创建的文件:
D:\python_cuijianzhe>tree /f
└─scrapy_test
│ scrapy.cfg #配置文件
│
└─scrapy_test #工程模块
│ items.py
│ middlewares.py #定义数据条目的定义,可以理解为一行记录
│ pipelines.py #定义数据导出类,用于数据导出
│ settings.py #工程设置文件
│ __init__.py #空文件
│
├─spiders #爬虫目录
│ │ __init__.py #空文件
│ │
│ └─__pycache__
└─__pycache__
在 scrapy_test 项目中的目录 spiders 中创建文件 quotes_spider.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
我们的 Spider 子类 scrapy.Spider 并定义了一些属性和方法:
这个命令使用我们刚刚添加引号的名字 name = "quotes" 运行 spider,它将发送一些对 quotes.toscrape.com 的请求。将得到如下输出:
D:\python_cuijianzhe\scrapy_test>scrapy crawl quotes
2019-11-08 14:16:33 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: scrapy_test)
2019-11-08 14:16:33 [scrapy.utils.log] INFO: Versions: lxml 4.4.1.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.7.0, Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20)
[MSC v.1916 64 bit (AMD64)], pyOpenSSL 19.0.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0
2019-11-08 14:16:33 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'scrapy_test', 'NEWSPIDER_MODULE': 'scrapy_test.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['scrapy_test.spiders']}
2019-11-08 14:16:33 [scrapy.extensions.telnet] INFO: Telnet Password: 118fc5b3a4cf7fef
2019-11-08 14:16:33 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2019-11-08 14:16:33 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2019-11-08 14:16:33 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-11-08 14:16:33 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2019-11-08 14:16:33 [scrapy.core.engine] INFO: Spider opened
2019-11-08 14:16:33 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-11-08 14:16:33 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2019-11-08 14:16:34 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2019-11-08 14:16:35 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None)
2019-11-08 14:16:35 [quotes] DEBUG: Saved file quotes-1.html
2019-11-08 14:16:35 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/2/> (referer: None)
2019-11-08 14:16:35 [quotes] DEBUG: Saved file quotes-2.html
2019-11-08 14:16:35 [scrapy.core.engine] INFO: Closing spider (finished)
2019-11-08 14:16:35 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
...
2019-11-08 14:16:35 [scrapy.core.engine] INFO: Spider closed (finished)
运行爬虫后, 会提示一堆的信息,主要是完成以下几个部分工作:
现在,检查当前目录中的文件。已经创建了两个新文件:quotes-1.html 和 quotes-2.html,其中包含了各自 url 的内容,正如我们的解析方法。
D:\python_cuijianzhe\scrapy_test>scrapy shell "http://quotes.toscrape.com/page/1/"
2019-11-08 14:27:53 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: scrapy_test)
2019-11-08 14:27:53 [scrapy.utils.log] INFO: Versions: lxml 4.4.1.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.7.0, Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20)
...
使用 shell,可以尝试使用 CSS 和 response 对象选择元素:
In [1]: response.css('title')
Out[1]: [<Selector xpath='descendant-or-self::title' data='<title>Quotes to Scrape</title>'>]
运行 response.css('title')的结果是一个名为 Selector list 的类似列表的对象,它表示一个 Selector 对象列表,这些对象环绕 XML/HTML 元素,并允许运行进一步的查询来细化选择或提取数据。
In [2]: response.css('title::text').getall()
Out[2]: ['Quotes to Scrape']
这里有两件事需要注意:
一是我们在 CSS 查询中添加了 ::text ,这意味着我们只想直接在
::text ,我们将得到完整的 title 元素,包括它的标记:
In [3]: response.css('title').getall()
Out[3]: ['<title>Quotes to Scrape</title>']
另一个是,调用 .getall() 的结果是一个列表:选择器可能返回多个结果,因此我们将它们全部提取出来。当你知道你只想得到第一个结果时,在这种情况下,可以使用:
In [4]: response.css('title::text').get()
Out[4]: 'Quotes to Scrape'
另外,可以这么写:
In [5]: response.css('title::text')[0].get()
Out[5]: 'Quotes to Scrape'
In [6]: response.css('title::text').re(r'Quotes.*')
Out[6]: ['Quotes to Scrape']
In [7]: response.css('title::text').re(r'Q\w+')
Out[7]: ['Quotes']
In [8]: response.css('title::text').re(r'(\w+) to (\w+)')
Out[8]: ['Quotes', 'Scrape']
参考 Xpath 实例
除了 CSS,Scrapy 选择器还支持使用 XPath 表达式:
In [9]: response.xpath('//title')
Out[9]: [<Selector xpath='//title' data='<title>Quotes to Scrape</title>'>]
In [10]: response.xpath('//title/text()').get()
Out[10]: 'Quotes to Scrape'
既然您已经对选择和提取有了一些了解,那么让我们通过编写代码从 Web 页面提取引号来完成 spider。
http://quotes.toscrape.com 中的每个引号都由如下所示的 HTML 元素表示:
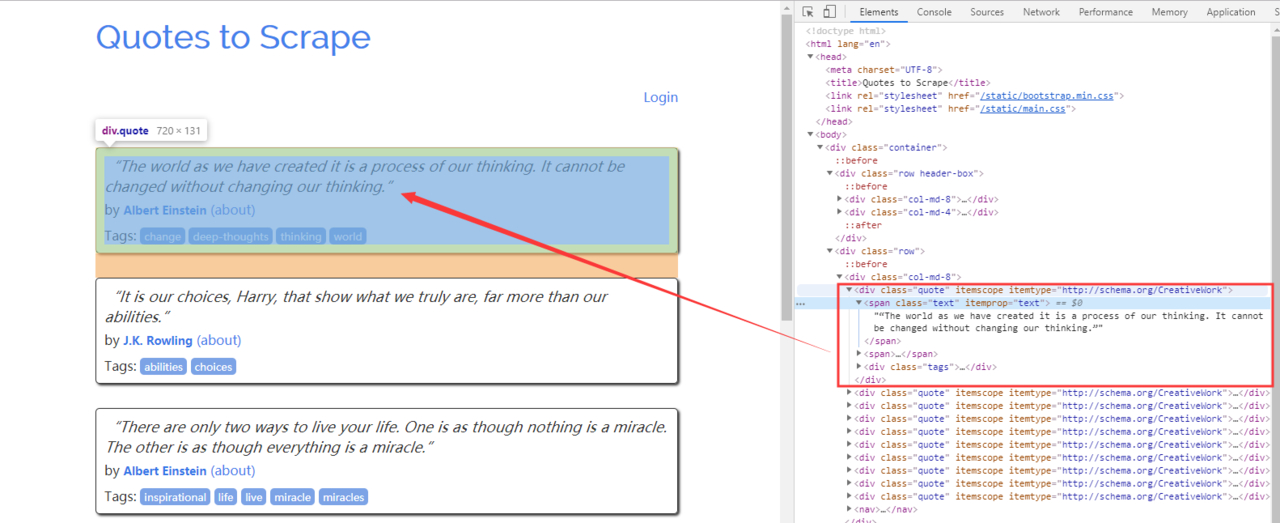
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world">
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
让我们打开 scrapy shell 并输出数据,了解如何提取所需的数据:
D:\python_cuijianzhe\scrapy_test>scrapy shell "http://quotes.toscrape.com"
2019-11-08 14:51:13 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: scrapy_test)
2019-11-08 14:51:13 [scrapy.utils.log] INFO: Versions: lxml 4.4.1.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.7.0, Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20)
[MSC v.1916 64 bit (AMD64)], pyOpenSSL 19.0.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0
2019-11-08 14:51:13 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'scrapy_test', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'scrapy_test.
spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['scrapy_test.spiders']}
2019-11-08 14:51:13 [scrapy.extensions.telnet] INFO: Telnet Password: b9273deb5a53cb00
2019-11-08 14:51:13 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2019-11-08 14:51:13 [scrapy.middleware] INFO: Enabled downloader middlewares:
...
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-11-08 14:51:13 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2019-11-08 14:51:13 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2019-11-08 14:51:13 [scrapy.core.engine] INFO: Spider opened
2019-11-08 14:51:14 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2019-11-08 14:51:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com> (referer: None)
...
我们得到了 quote HTML 元素的选择器列表,其中包含:
In [1]: response.css("div.quote")
Out[1]:
[<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>]
上面查询返回的每个选择器都允许我们对其子元素运行进一步的查询。让我们将第一个选择器分配给一个变量,这样就可以直接在特定的引号上运行 CSS 选择器:
In [2]: quote = response.css("div.quote")[0]
现在,使用刚刚创建的 quote 对象从该 quote 中提取 text、author 和 tags:
In [3]: text = quote.css("span.text::text").get()
In [4]: text
Out[4]: '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'
In [5]: author = quote.css("small.author::text").get()
In [6]: author
Out[6]: 'Albert Einstein'
鉴于 tags 是字符串列表,我们可以使用 .getall() 方法获取所有 tags:
In [7]: tags = quote.css("div.tags a.tag::text").getall()
In [8]: tags
Out[8]: ['change', 'deep-thoughts', 'thinking', 'world']
在知道如何提取每个位之后,现在可以遍历所有引号元素,并将它们放在一个 Python 字典中:
In [9]: for quote in response.css("div.quote"):
...: text = quote.css("span.text::text").get()
...: author = quote.css("small.author::text").get()
...: tags = quote.css("div.tags a.tag::text").getall()
...: print(dict(text=text, author=author, tags=tags))
...:
{'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Albert Einstein', 'tags': ['change', 'deep-thoughts', 'thinking',
'world']}
{'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', 'author': 'J.K. Rowling', 'tags': ['abilities', 'choices']}
{'text': '“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”', 'author': 'Albert Einstein', 'tags': ['inspirational', 'life
', 'live', 'miracle', 'miracles']}
{'text': '“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”', 'author': 'Jane Austen', 'tags': ['aliteracy', 'books', 'classic', 'humor']}
{'text': "“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”", 'author': 'Marilyn Monroe', 'tags': ['be-yourself', 'inspirational']}
{'text': '“Try not to become a man of success. Rather become a man of value.”', 'author': 'Albert Einstein', 'tags': ['adulthood', 'success', 'value']}
{'text': '“It is better to be hated for what you are than to be loved for what you are not.”', 'author': 'André Gide', 'tags': ['life', 'love']}
{'text': "“I have not failed. I've just found 10,000 ways that won't work.”", 'author': 'Thomas A. Edison', 'tags': ['edison', 'failure', 'inspirational', 'paraphrased']}
{'text': "“A woman is like a tea bag; you never know how strong it is until it's in hot water.”", 'author': 'Eleanor Roosevelt', 'tags': ['misattributed-eleanor-roosevelt']}
{'text': '“A day without sunshine is like, you know, night.”', 'author': 'Steve Martin', 'tags': ['humor', 'obvious', 'simile']}
Scrapy spider 通常生成许多字典,其中包含从页面提取的数据。为此,我们在回调中使用 yield Python 关键字,如下所示:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
运行此 spider,它将输出提取的数据和日志:
D:\python_cuijianzhe\scrapy_test>scrapy crawl quotes
2019-11-08 15:01:27 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: scrapy_test)
2019-11-08 15:01:27 [scrapy.utils.log] INFO: Versions: lxml 4.4.1.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.7.0, Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20)
[MSC v.1916 64 bit (AMD64)], pyOpenSSL 19.0.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0
2019-11-08 15:01:27 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'scrapy_test', 'NEWSPIDER_MODULE': 'scrapy_test.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['scrapy_test.spiders']}
2019-11-08 15:01:27 [scrapy.extensions.telnet] INFO: Telnet Password: 4914bcc0ab6bc5c7
2019-11-08 15:01:27 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2019-11-08 15:01:28 [scrapy.middleware] INFO: Enabled downloader middlewares:
...
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
...
2019-11-08 15:01:29 [scrapy.core.engine] INFO: Spider closed (finished)
D:\python_cuijianzhe\scrapy_test>scrapy crawl quotes -o quotes.json
D:\python_cuijianzhe\scrapy_test>scrapy crawl quotes -o quotes.xml
D:\python_cuijianzhe\scrapy_test>scrapy crawl quotes -o quotes.csv
D:\python_cuijianzhe\scrapy_test>scrapy crawl quotes -o quotes.jl
既然知道了如何从页面中提取数据,那么看看如何跟踪页面中的链接
<ul class="pager">
<li class="next">
<a href="/page/2/">Next <span aria-hidden="true">→</span></a>
</li>
</ul>
我们可以试着从 shell 中提取出来:
In [1]: response.css('li.next a').get()
Out[1]: '<a href="/page/2/">Next <span aria-hidden="true">→</span></a>'
这将获取锚定元素,但我们需要属性 href。为此,Scrapy 支持 CSS 扩展,允许您选择属性内容,如下所示:
In [2]: response.css('li.next a::attr(href)').get()
Out[2]: '/page/2/'
还有一个 attrib 属性可用(有关详细信息,请参见选择元素属性):
In [3]: response.css('li.next a').attrib['href']
Out[3]: '/page/2/'
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
代码简介:
next_page 是我们从页面提取的下一页的网址,然后 urljoin 去拼接完整 url,然后使用 request 去请求下一页,还是使用 parse 去解析响应流,当然我们可以在写一个 parse 的。
这段代码执行后发现后面几页全部住取出来了
代码示例:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
url = 'http://quotes.toscrape.com/'
tag = getattr(self, 'tag', None)
if tag is not None:
url = url + 'tag/' + tag
yield scrapy.Request(url, self.parse)
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
这些参数被传递给 Spider 的__init__方法,并在默认情况下成为 Spider 属性。
在本例中,为 tag 参数提供的值可以通过 self.tag 获得。您可以使用此选项使爬行器仅获取带有特定标记的引号,并基于参数构建 URL:
通过在运行 spider 时使用-a 选项,可以为它们提供命令行参数:
<a class="tag" href="/tag/choices/page/1/">choices</a>
D:\python_cuijianzhe\scrapy_test>scrapy crawl quotes -o quotes-humor.json -a tag=choices
 邯城往事
邯城往事